

At HackerRank, AWS Elastic Kubernetes Service (EKS) is central to our infrastructure, supporting critical applications and services with scalability, performance, and security at its core.
Regular EKS upgrades are more than a technical necessity—they directly impact business outcomes.
This blog details our meticulous approach to EKS upgrades, the tools and workflows powering them, and the lessons we’ve learned to keep our infrastructure not just operational, but a competitive advantage in the tech landscape.
Why Do We Need Regular EKS Upgrades?
Kubernetes and its ecosystem are constantly evolving, which makes regular upgrades crucial for maintaining a secure, efficient, and competitive environment. Key reasons for timely upgrades include:
| Reason | Key Benefits |
|---|---|
| 🛡 Security | Patches address vulnerabilities and prevent exploits. |
| ⚡ Performance | New versions optimise resource management for better performance. |
| 🌟 New Features | Access the latest capabilities like enhanced networking, scaling, and workload management. |
| 🤝 AWS Support | Avoid costs with extended support fees. AWS offers Standard Support for 12 months, including patches and updates. Post this, versions move to Extended Support (6–12 months) at a higher cost with limited fixes. |
1000-Foot Overview of HackerRank’s Infrastructure
Workflow
A simple workflow diagram illustrating the flow from non-prod environments to production.

- Any infrastructure or application release typically goes through the above 4 environments.
HackerRank’s Infrastructure Overview
We maintain approximately 14 EKS clusters serving diverse purposes:
- Application Workloads: Application services.
- Data Platform: Staging and Production clusters.
- Unit Testing and ArgoCD: Dedicated clusters.
- Performance Testing: Ondemand “performance” clusters.
We upgrade EKS clusters twice a year, aiming to remain on the n-1 version of Kubernetes. For instance, if v1.30 is the latest, our target is v1.29.
Tools and Workflow
- Application Workload Management: Helm charts integrated with ArgoCD.
- EKS Infrastructure Support: EKS cluster specific Helm charts for logging, monitoring, and resilience tools are in place.
- Version Management: All Helm charts are stored in a GitHub repository and deployed via ArgoCD.
Pre-Upgrade Preparation
1. Review Kubernetes Target Version Release Notes
Review the Kubernetes release notes for features, deprecations, and breaking changes.
Kubernetes release notes provide a comprehensive overview of new features, bug fixes, security patches, and deprecated APIs in each version. Before upgrading EKS, we carefully review the release notes for the target version to identify any deprecated APIs, breaking changes, or updates that could potentially affect our workloads.
Release notes snippet:

2. Update Helm Charts
The Helm charts are updated to remove deprecated APIs and address any breaking changes introduced and ensure compatibility with the target Kubernetes version.
A feature branch is created in the Github repository to roll out these changes. The feature branch is first deployed to our non-production environments (Private, QA, and Preview) in sequence, where they undergo a series of sanity tests and validations (application compatibility, node health, networking, or security policies). Once the changes are verified and validated, the feature branch is merged into the master branch creating a new release. The new release is then deployed to production.
A diagram showcasing the process:
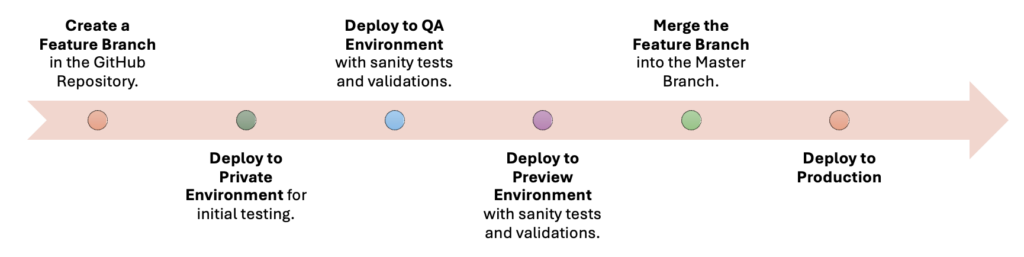
3. Update Documentation
Proper documentation is essential to ensure that all team members and stakeholders are aligned and fully understand the changes introduced by an EKS upgrade as well as maintain configuration uniformity across all environments.
Our upgrade notes include:
- The list of K8s API deprecations and breaking changes affecting our workloads and the updates made to our helm charts.
- The current version and the latest compatible version of VPC CNI, Kube-Proxy and CoreDNS. They can be fetched using the below AWS CLI commands.
- The latest compatible AMI IDs and names corresponding to the target EKS version. They can be found at awslabs amazon eks releases page.
- All the necessary AWS CLI and kubectl commands to initiate the EKS upgrade, upgrade key components, and roll back the upgrades in case of any issues are kept readily available.
VPC CNI :
aws eks describe-addon-versions \
--addon-name vpc-cni \
--kubernetes-version <target-version> \
--query "addons[].addonVersions[0].addonVersion" \
--output text \
--region <aws-region>
Kube-Proxy :
aws eks describe-addon-versions \
--region <aws-region> \
--addon-name kube-proxy \
--kubernetes-version <target-version> \
--query "addons[].addonVersions[].[addonVersion, compatibilities[].defaultVersion]" \
--output text | head -n 1 | awk '{print $1}'CoreDNS :
aws eks describe-addon-versions \
--region <aws-region> \
--addon-name coredns \
--kubernetes-version <target-version> \
--query "addons[].addonVersions[].[addonVersion, compatibilities[].defaultVersion]" \
--output text | head -n 1 | awk '{print $1}'4. Check Upgrade Insights on AWS Console
Before starting the EKS upgrade process, it’s crucial to understand the health and readiness of the cluster for an upgrade. The “Upgrade Insights” tab in AWS EKS console provides a detailed report on any issues or incompatibilities that could affect the upgrade process. We ensure that all upgrade insights are passing, and address any issues before continuing to the next steps.
Note: Any API deprecations related to EKS control plane API’s cannot be fixed by us and are taken care of on AWS side.
Screenshot: screenshot of AWS’s “Upgrade Insights” tab.
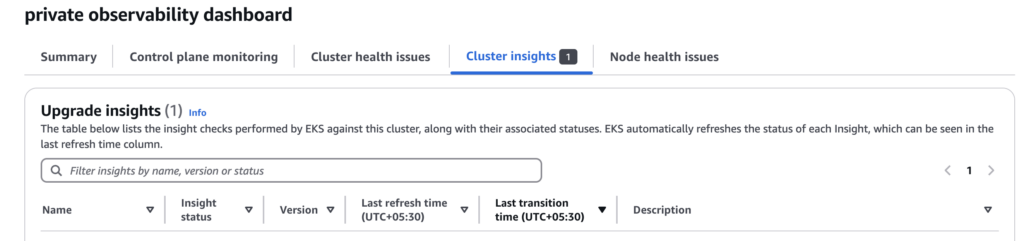
Ref: AWS Upgrade Insights.
5. Perform EKS Upgrade in all the Non-Prod Environments
EKS clusters in all non-production environments are upgraded and thoroughly validated.
6. Communicate Upgrade Window to Stakeholders
Before the production EKS upgrade, all key stakeholders are notified with scheduled EKS upgrade date, time window (typically 07:00 AM IST to 09:00 AM IST – since this is our low-traffic period) and potential impact on the production environment on the engineering-team slack channel. It is ensured that the upgrade activity is communicated well in advance at least 48 hours ago.
We also send out a reminder just 15 minutes before the scheduled activity. A final reminder ensures that everyone is ready for the upgrade to start and no critical work is left pending during the upgrade window.
Production Upgrade Process
This guide outlines the key steps for upgrading each components in Amazon EKS clusters. The goal is to ensure zero disruption to production workloads.
Visualize this process:

1. Upgrading the EKS Control Plane

The Kubernetes control plane acts as the central component of an Amazon EKS cluster. Upgrading the control plane is the first and most critical step in the EKS upgrade process. Here’s how you can trigger the upgrade:
Command to Upgrade the Control Plane
Use the following AWS CLI command to initiate the upgrade:
aws eks update-cluster-version --name <eks-cluster> --kubernetes-version <target-version> --region <aws-region>Expected Duration: The upgrade typically takes 10–15 minutes to complete.
Our Experience During a Production Upgrade
During a recent production EKS upgrade, we encountered a notable issue:
- The process got stuck in the ‘Updating’ phase ⏱️ for over an hour.
- Since the EKS control plane upgrade is fully managed by AWS, we had no direct control.
What Happened: At this point, we had to wait for one of two outcomes:
- ✅ The process completes successfully.
- 🔄 The upgrade rolls back automatically.
Impact: No workloads were impacted because AWS EKS uses a blue-green deployment approach for control plane upgrades.
2. Upgrade Autoscaling Group (ASG) Nodes

We use self-managed node groups. After upgrading the control plane, follow these steps to upgrade ASGs:
Note: To avoid any interruptions to production workloads, we do not trigger an automatic instance refresh.
Step 1: List All Launch Templates
aws ec2 describe-launch-templates --query "LaunchTemplates[*].[LaunchTemplateName]" --output text --regionRun the following to retrieve existing launch templates:
Step 2: Get the Latest Version Number
Identify the launch template version to update:
aws ec2 describe-launch-template-versions --launch-template-name <launch-template-name> \
--query 'LaunchTemplateVersions[0].VersionNumber' --output text --region <aws-region>Step 3: Create a New Launch Template Version
Update the launch template with the new AMI ID:
aws ec2 create-launch-template-version --launch-template-name <launch-template-name> \
--version-description "Updated to <target-ami-id> for EKS <target-version>" \
--source-version <launch-template-version> \
--launch-template-data "{\"ImageId\":\"<target-ami-id>\"}" --region <aws-region>Step 4: Update Autoscaling Groups
List ASGs associated with the launch template:
aws autoscaling describe-auto-scaling-groups \
--query "AutoScalingGroups[?MixedInstancesPolicy.LaunchTemplate.LaunchTemplateSpecification.LaunchTemplateName=='<launch-template-name>'].AutoScalingGroupName" \
--output text \
--region <aws-region>Update ASGs to use the new launch template version:
aws autoscaling update-auto-scaling-group --auto-scaling-group-name "<asg-name>" \
--launch-template LaunchTemplateName="<launch-template-name>", \
Version="<latest-launch-template-version>" --region <aws-region>Outcome: New nodes use the updated AMI. Rollback is possible by reverting the ASG to the previous template version.
3. Upgrading Kubernetes Add-Ons

To ensure compatibility and optimal cluster performance, the CoreDNS, VPC CNI, and Kube-Proxy add-ons are upgraded sequentially to their latest versions using the kubectl command-line utility.
Key Considerations 📌
- We maintain a record of the current add-on versions for rollback purposes.
- If issues arise during the upgrade, the same commands can be used to revert to the previous versions.
CoreDNS Update
Update CoreDNS to the latest compatible version:
kubectl set image --namespace kube-system deployment.apps/coredns \
coredns=602401143452.dkr.ecr.us-east-1.amazonaws.com/eks/coredns:<latest-version>- Replace <latest-version> with the latest CoreDNS version (e.g., v1.11.3-eksbuild.1).
- Verify the update to ensure the new pods are running successfully:
kubectl get pods -n kube-system -l k8s-app=kube-dnsVPC CNI Update
Step 1: Download the Target Version
Retrieve the desired VPC CNI YAML file:
wget https://raw.githubusercontent.com/aws/amazon-vpc-cni-k8s/<version>/config/master/aws-k8s-cni.yamlReplace <version> with the latest compatible version (e.g., v1.18.5).
Step 2: Compare and Apply Changes
Use the kubectl diff command to compare the current configuration with the new one:
kubectl diff -f aws-k8s-cni.yamlApply the updated configuration if everything is in order:
kubectl apply -f aws-k8s-cni.yamlStep 3: For Clusters with Secondary CIDR
Set the following variable in the aws-k8s-cni.yaml file:
AWS_VPC_K8S_CNI_CUSTOM_NETWORK_CFG = trueKube-Proxy Update
Update Kube-Proxy to the latest compatible version:
kubectl set image daemonset.apps/kube-proxy -n kube-system \
kube-proxy=602401143452.dkr.ecr.us-east-1.amazonaws.com/eks/kube-proxy:<latest-version>- Replace <latest-version> with the desired Kube-Proxy version (e.g., v1.29.7-eksbuild.9).
- Validate the changes:
kubectl get daemonset kube-proxy -n kube-system4. Delete Warmpool

EKS warmpools consist of pre-provisioned EC2 instances in an inactive (warmed) state, ready to scale up quickly when required. These instances use older AMIs before the upgrade.
- Action: Delete the existing warmpool to clear out nodes with outdated AMIs.
- Result: New instances with updated AMIs will be launched automatically once the upgrade process is complete.
5. Node Tainting and Autoscaling Group Capacity Adjustment 📈

To ensure workloads are migrated to nodes with the upgraded AMIs:
Step 1: Taint Old Nodes
Use the kubectl command to taint existing nodes, preventing new pods from being scheduled on them:
kubectl taint nodes --all env=production:NoScheduleStep 2: Adjust Autoscaling Group Capacity
Increase the desired capacity of the Auto Scaling Group (ASG) to twice the current node count. This triggers the creation of new nodes with the updated AMIs.
- Why?: The additional capacity ensures workloads are scheduled on the new nodes gradually while maintaining availability.
6. Rollout Restart of Deployments

Once new nodes are provisioned, we trigger a rollout restart of all workloads running on the EKS cluster. This is done sequentially via ArgoCD or kubectl:
kubectl rollout restart deployment <deployment-name>What Happens During a Rollout Restart?
- Kubernetes performs a rolling update, restarting pods one at a time.
- With taints applied to old nodes, new pods are scheduled only on the upgraded nodes.
This ensures zero downtime for applications during the restart process.
7. Post-Upgrade Validation

After completing the upgrade:
- Monitor Alerts: Check observability tools (e.g., CloudWatch, Prometheus) for any alerts.
- Verify Workloads: Trigger a test deployment to validate that workloads are running as expected and applications are accessible.
📌 Note: While the control plane cannot be rolled back, node group versions support rollback up to n-2 versions.
8. Revert Autoscaling Group Capacity Adjustment

Once the upgrade is validated:
- Restore ASG Capacity: Reset the desired capacity to its original value.
- Recreate Warmpool: Reprovision the warm pool to match the original configuration.
Termination Policy
Ensure the termination policy in the launch template is set to OldestInstance to:
- Prioritize termination of nodes using older AMIs.
- Seamlessly migrate workloads to the updated nodes without disruption.
9. Notify Stakeholders
Finally, inform all stakeholders about the successful completion of the upgrade.
Challenges in EKS Upgrades
While automation has helped, we still face a few challenges:
- Time-Consuming Process:
With 14 EKS clusters, upgrading each cluster sequentially is labor-intensive, taking 4-5 weeks for completion. - Manual Steps and Human Errors:
The reliance on manual processes increases the risk of human error, causing inconsistencies or upgrade failures. - Helm Chart Limitations:
The infra-system Helm chart (an umbrella chart) has constraints within the ArgoCD ecosystem:- Excessive refresh times.
- Only “OutOfSync” changes are applied.
- Rollbacks are complex and time-consuming.
- Inconsistent IaC Adoption:
While some EKS clusters are managed with Terraform, others follow manual processes. This inconsistency complicates management and introduces inefficiencies.
Learnings and Improvements
During our journey with EKS upgrades, we encountered challenges and inefficiencies that provided valuable lessons. Here’s what we learned and the improvements we’ve made:
1. Overcoming Upgrade Lag
Initially, we fell behind on the EKS upgrade cadence, forcing us to perform multi-version upgrades (e.g., two versions at once). This created additional overhead due to the repeated steps required for each version.
2. Automation: A Game-Changer
To streamline the process, we developed a Bash script that automates most upgrade tasks using:
- AWS CLI
- kubectl
With this script, we can now complete EKS upgrades across all environments, including production, within 2 weeks from 4 weeks . This automation has significantly improved our ability to stay up-to-date with Kubernetes’ release cycle of 3-4 versions per year.
Current State: Our clusters are consistently upgraded to n-1 versions, ensuring better security, stability, and feature compatibility.
3. Planned Improvements
To address these challenges and further optimize our upgrade process, we plan to:
1. Incorporate Infrastructure-as-Code (IaC)
- Adopt IaC (e.g., Terraform) across all EKS clusters.
- This will bring consistency, improve management, and reduce manual intervention, lowering the risk of errors.
2. Move to Karpenter
By leveraging Karpenter, we can:
- Roll out AMI changes to worker nodes gradually.
- Drift a maximum of one node at a time, ensuring minimal disruption and improved cluster stability.
3. Refactor Infra-System Helm Charts
- Split the current umbrella Helm charts into smaller, modular charts.
- Benefits include:
- Improved flexibility in ArgoCD.
- Reduced refresh times.
- Simplified rollbacks when needed.
Conclusion 🎯
EKS upgrades are crucial for maintaining a secure, scalable, and high-performing Kubernetes infrastructure. We follow a structured, meticulous process to minimize disruption and ensure smooth execution:
- Automation has reduced upgrade timelines and manual effort.
- Best practices—from pre-upgrade documentation to post-upgrade validation—ensure minimal impact on production workloads.
- Continuous improvements like moving to Karpenter and increasing IaC adoption will further enhance efficiency and cluster stability.
Through these strategies, we’ve successfully optimized EKS upgrades across our environments. By adopting similar practices, your organization can streamline its EKS upgrade process, ensuring reliability, scalability, and operational excellence for Kubernetes workloads.

Sushil – Sr. Engineering Manager, HackerRank
Sushil is a seasoned engineering leader with extensive experience in managing and optimizing cloud infrastructure. As the Senior Engineering Manager at HackerRank, oversees the architecture, deployment, and scaling of cloud-based systems to support the platform’s global operations.
Leave a Reply