
The Beginning
It was business as usual at the HackerRank office. As the HackerRank Community team gathered to plan the next quarter, one of the topics that came up was the Tech debt we will address this quarter.
To give some context, every quarter in our team we pick two Tech debt items – one on each Backend & Frontend alongside all the product items that we have to build.
After some discussion, we finally decided to pick MySQL Upgrade to 8 as one of the items. It was a long due.
Motivation for Upgrade
Why did we need to upgrade to MySQL 8.0? We had been running AWS Relational Database Service (RDS) with extended support for MySQL 5.7, as it had reached its end of life. However, this extended support came at a steep cost—an additional $3,000 per month. It was time to upgrade to a version of MySQL that would provide the latest security updates, bug fixes, and performance enhancements but more importantly, time to save that money.
And so, the roller coaster began: upgrading the HackerRank Community Database from MySQL 5.7 to 8.
Honestly, I was the most excited about this upgrade. Reading the High-Performance MySQL book, I was eager to dive into the core infrastructure changes. It was finally time for some database fun!
A sneak peek into the HackerRank’s Infrastructure
Now, our AWS RDS setup looks like this:
- Master, where all the reads and writes are directed to
- Read Replica, where all the long-running reads are directed to
- Analytics Replica, which is used for our internal analytics
Now, as a next step, we had to devise a plan for the upgrade and what all prerequisites would be needed to be performed to get the upgrade done.
Approach to the Upgrade
As we delved deeper into upgrading our RDS instance, we explored using AWS’s Blue/Green deployment.
Amazon RDS Blue/Green deployment solution is simple, and most of the replication/sync effort between existing MySQL 5.7 (blue deployment) and MySQL 8 (green deployment) is managed by AWS using logical replication. You can make changes to the RDS DB instances in the green environment without affecting production workloads like upgrading the DB engine version or changing database parameters in the staging environment.
When ready, you can switch over the environments to promote the green environment as the new production environment. The switchover typically takes under a minute with no data loss and no need for application changes.
One key prerequisite for this approach was ensuring that both the master and replicas had identical indexes, with no separate read indexes on the replicas. We took an SQL dump of all three databases to verify this and compared the indexes. Thankfully, all three had matching indexes, so we proceeded with the Blue/Green deployment. One problem solved!
Preparing for the Upgrade
With the upgrade method confirmed to be Blue/Green (rather than the traditional method of creating a duplicate RDS and switching traffic), we outlined the necessary steps:

After running the upgrade-checker tool, we encountered one error due to an intermediate temporary table. This was resolved by dropping the table. The error message was:
[ERROR] Schema inconsistencies resulting from file removal or corruption.This issue likely stemmed from an ALTER command being interrupted prematurely.
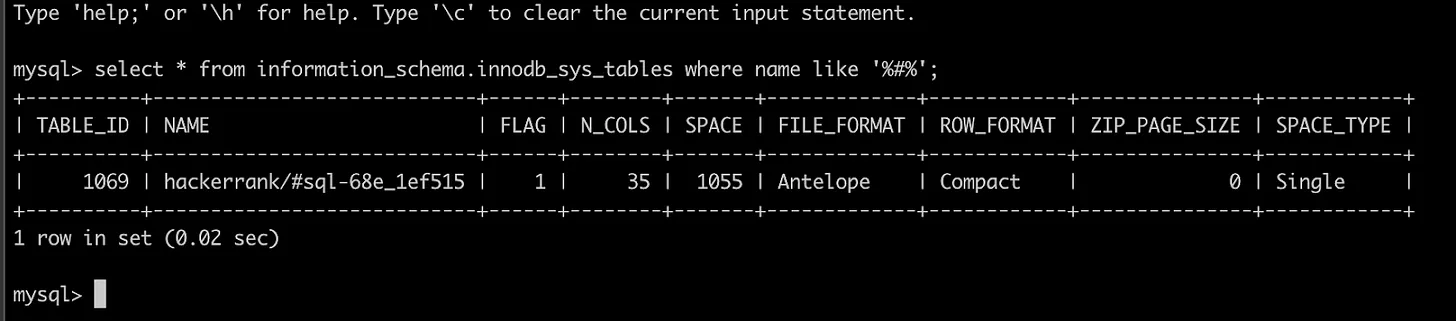
Reference: https://serverfault.com/questions/1002704/cant-upgrade-rds-instance-from-mysql-5-7-x-to-8-0-x
Once this error was fixed, we successfully set up the non-production blue/green environment.

We conducted thorough regression testing, which showed that our application was compatible with MySQL 8 and that no major code changes were necessary.
After completing the tests, we upgraded all non-production environments to MySQL 8. The next step was to implement Blue/Green deployment in production.

In the production environment, we resolved the same error and got MySQL 8 running in the green environment.
However, since production had two replicas and also 4 TB worth of data, we experienced a significant replication lag for around 2 days. We tried multiple approaches like changing the parameter value like slave_parallel_workers to a higher value and recreating the Blue/Green setup but that did not seem to get the lag down. One of the other things we tried was, we initiated a mysqldump and increased the IOPS (Input/Output Operations Per Second).
Running a mysqldump operation on your read replica allows Amazon RDS to prioritize and download all of the backed-up table data from Amazon Simple Storage Service (Amazon S3) thus helping in getting the lag down.
This slowly brought the replication lag down to 0, just 15 hours before the scheduled time for the production maintenance window.

Once the lag was back to 0, we started to change the parameter group from default MySQL 8 to the desired ones for our database and upgraded the instance to the graviton. As soon as we did this, we encountered an error
REPLICATION_ERROR/Replica failed to initialize applier metadata structure from the repository.This was caused due to an unexpected server halt that was triggered by Multi-AZ failover on the green instance and failover was expected. While we were trying to resolve the above issue, there came another twist…
The Twist
As Murphy’s law states, anything that can go wrong will go wrong. Here’s the twist: we encountered a warning in the logs that seemed innocuous at first, but in reality, it was a fatal error.
2024-07-20T04:24:44.767492Z 13 [Warning] [MY-011825] [InnoDB]
Cannot add field `codechecker_time` in table `hackerrank`.`h_submission_shards_co_1_ch_520` because after adding it, the row size is 8827, greater than the maximum allowed size (8126) for a record on the index leaf page.This issue arose because the row_format for some tables was set to Compact, while MySQL 8 uses Dynamic as the default format.
Upon deeper investigation, revealed a serious issue that could lead to potential data corruption. This would render all tables with the earlier error inaccessible. Surprisingly, none of this was flagged in the PrePatchCompatibility logs during the upgrade process.
What was the Issue?
Before MySQL 5.7, the default row_format was Compact. Many of our tables had been created when we were using MySQL 5.6. When we upgraded from 5.6 to 5.7 back in 2018, all newly created tables adopted the Dynamic row format, which is also the default in MySQL 8 & 5.7. However, we never updated row_format of the older tables during the 5.6 to 5.7 upgrade. Now, during the upgrade to MySQL 8, these old tables triggered errors due to the large amount of data they contained.
This issue only surfaced in production because the database there holds significantly more data than in non-production environments. The larger data volume caused the database to start throwing errors.
References:
The only way to resolve this issue was to update the row_format to Dynamic MySQL 5.7 before performing the upgrade. And so, like every great movie, for our database upgrade one rollout plan wasn’t enough— here comes Rollout 2.0, bigger and full of twists!
Rollout 2.0
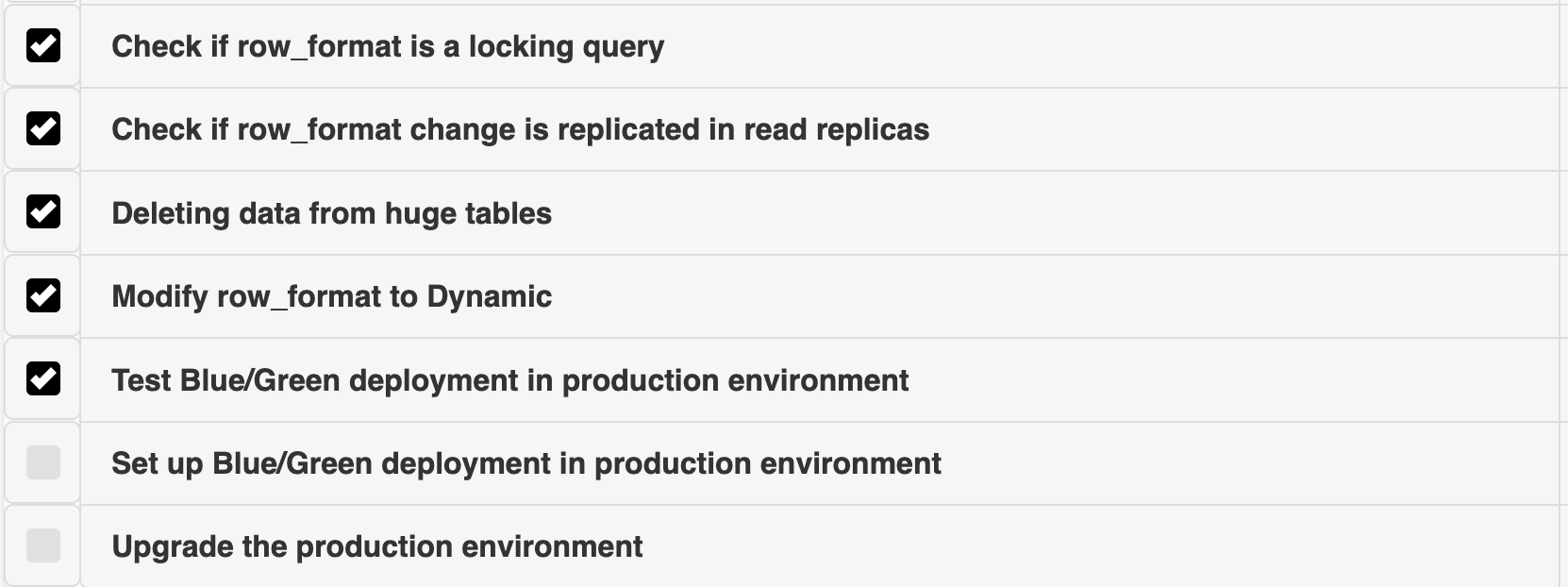
The next step was to verify whether changing the row_format would be a blocking call. These are the set of tasks that we started with,

We tested the row_format changes in the lower environment and confirmed that it is a non-blocking change. This means it allows DML/DDL operations on the table while it’s being modified. MySQL documentation also confirmed that this change is non-blocking, which was a relief.


The next concern was whether this change on the master would be replicated in the read replicas.
To verify this, we created a temporary database from the existing master snapshot with one replica. There were 2 ways to modify the row_format
OPTIMIZE TABLE <table_name>ALTER TABLE <table_name> ROW_FORMAT = DYNAMIC;
This is what the OPTIMIZE TABLE does; it essentially rebuilds the table for InnoDB. It performs a process that involves creating a temporary table with the optimized structure and data which means it will also set the row_format to default value, copying the data into it, and then replacing the original table with the optimized one. This process results in defragmentation and compaction, which can reclaim disk space and improve performance.
We decided to go ahead with the OPTIMIZE TABLE command and not do ALTER because of the following reasons:
- Performing the
ALTERstatement explicitly sets a value ofrow_format=DYNAMICundercreate_optionsfor the table, even though it matches the current default. Setting an explicit row format on the table is something we may need to be aware of if we ever choose to change row formats in the future. OPTIMIZE TABLEcommand also changes the row format of the table to the current default, but does so without setting create_options;
We modified the row_format to Dynamic using the OPTIMIZE TABLE command and confirmed that the changes were successfully replicated to the read replica. This verification was crucial because we couldn’t run any ALTER commands directly on the replica, as it has read_only=1.

After these tests, we realized the only way to modify the row_format to Dynamic in production was by running the OPTIMIZE TABLE command directly on the production master.
Yet again, there was an unexpected turn. The OPTIMIZE TABLE command works by creating a duplicate table, reading the current table’s online DML, and then switching to the new table. For this to succeed, the database needs enough free storage equal to the size of the table being optimized. Once the optimize is done, the storage is recovered. One of our tables was a massive 824 GB, but our AWS RDS had only limited free storage. To proceed with the OPTIMIZE command, we first had to clean up this table to free up the necessary storage. And this is how one more task got added to our checklist,
Deleting & Optimizing
To minimize the impact of running the OPTIMIZE command on our database, we first tested it on a small production table and noticed increased replica lag during execution. To mitigate this, we temporarily redirected all read traffic to the overprovisioned master server, which efficiently handled both reads and writes.
Our largest table was the 824 GB sessions table managed by Devise in Ruby on Rails, containing data since 2018. Since we only needed data from the past year, we wrote a deletion script to remove old records in batches of 10,000 with 1-second pauses between batches. Over a week, this reduced the table size to 124 GB, allowing us to run OPTIMIZE smoothly.
We also cleaned up unused archival tables, freeing an additional 1.5 TB of storage. We proceeded to run OPTIMIZE on all tables with a row_format of Compact, starting with the smaller ones and monitoring CPU usage to keep it below 80%.
However, we faced duplicate entry errors due to unique composite indexes on tables with high concurrent writes during the OPTIMIZE process. This occurred because OPTIMIZE rebuilds the table, and concurrent writes could cause duplicates in the new table. This is a bug in MySQL itself.
Reference: MySQL Bug #98600.
| Table | Op | Msg_type | Msg_text |
+--------------------------------+----------+----------+------------------------------------------------------------------------------------------------------+
| hackerrank.h_hacker_broadcasts | optimize | note | Table does not support optimize, doing recreate + analyze instead |
| hackerrank.h_hacker_broadcasts | optimize | error | Duplicate entry '26450629-2629173' for key 'index_h_hacker_broadcasts_on_hacker_id_and_broadcast_id' |
| hackerrank.h_hacker_broadcasts | optimize | status | Operation failedTo resolve this, we monitored traffic patterns to find low-traffic windows for running OPTIMIZE, which worked for some tables. For one problematic table, we temporarily dropped the unique composite index and implemented stricter code checks to prevent duplicates, allowing us to complete OPTIMIZE and re-add the index afterward.
For a particularly write-heavy table, we introduced a Redis flag with random sleep intervals between reads to prevent duplicate entries, enabling us to re-add the unique index successfully. In hindsight, implementing this Redis-based approach earlier could have avoided the need to drop indexes.
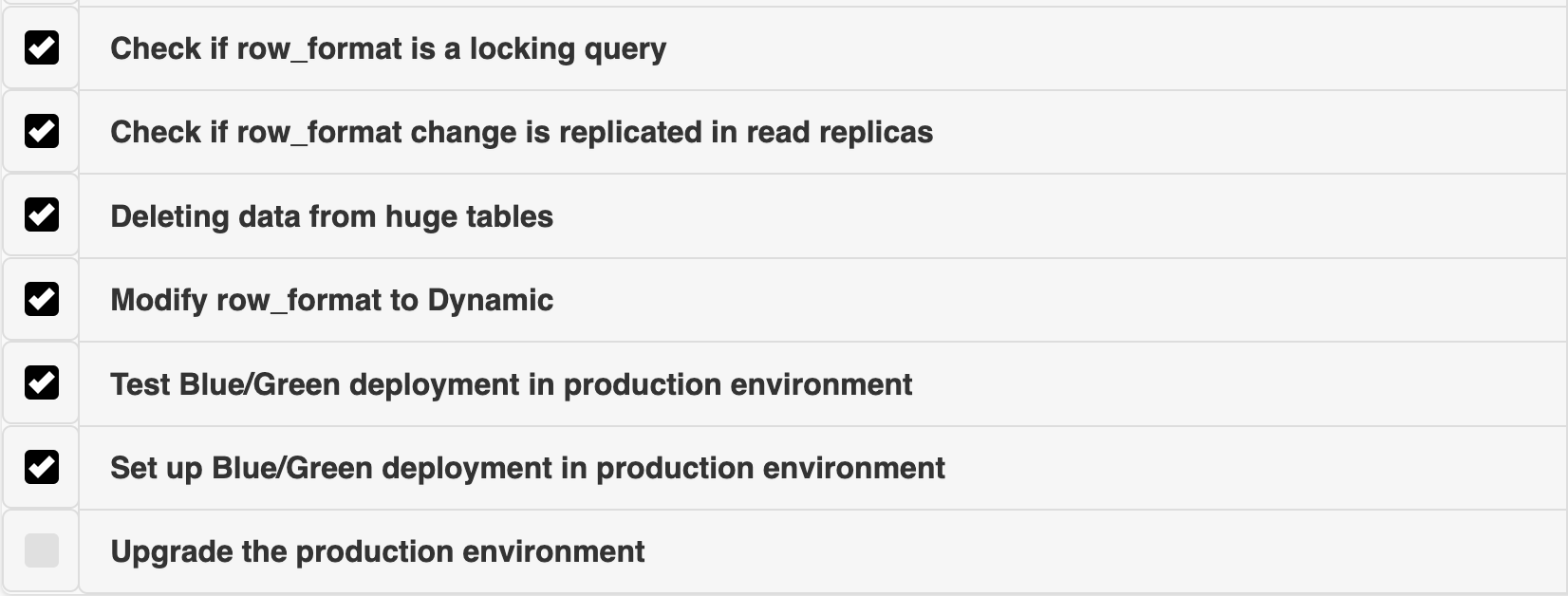
Ultimately, we updated all tables to have a row_format of DYNAMIC, solving a major issue. However, due to the extensive changes made to the master, the replicas were now experiencing significant lag.
Testing the Blue/Green Setup
The next step was setting up a Blue/Green deployment in production, updating the Green environment’s parameter group, and upgrading to Graviton. We began this process but also wanted to ensure we had clear metrics on how long the switchover would take in production. While AWS suggests a switchover time of 30 seconds to 2 minutes, we decided to test it cautiously due to the size of our RDS.
We created a temporary database with production changes, added a replica, and set up Blue/Green to benchmark the switchover time. During testing, we simulated the production load on the database and performed the switchover.
The switchover took 1 minute, with 2-3 seconds of downtime, giving us confidence that the upgrade would have minimal user impact.
Production Blue/Green Setup
Since we had been running the OPTIMIZE command in production, the read replica lag had become significantly high. To avoid any potential issues during the real switchover, we wanted to ensure that the lag was reduced to zero. To address this, we increased the IOPS on the active replica, which helped bring the lag down gradually.
Additionally, the Blue/Green setup on the production master was also experiencing lag. Based on our previous experience, we decided to disable Multi-AZ on the Green setup, start a mysqldump, and increase the IOPS. As a result, we observed the lag steadily decreasing.
One other warning we have been seeing in the logs was
DB Instance has a large number of tables and has the parameter innodb_file_per_table set to 1, which can increase database recovery time significantly. Consider setting this parameter to 0 in the parameter group associated with this DB instance to minimize database downtime during reboots and failovers.
We decided to keep it as 1 itself because It being turned on helped us reclaim storage space in AWS when we were running the OPTIMIZE command since each of the tables had its idb files. If it is off and we do the optimize, it cleans up the space but we can’t see the storage increase on the AWS level it will be maintained in the shared tablespace within MySQL itself, and MySQL will utilize it as new records are added.
The Endgame
Our upgrade was scheduled for August 31, 2024, at 10:30 AM IST. By this point, we were fully prepared, having thoroughly tested the application and the Blue/Green switchover.
The final switchover took less than a minute to complete with zero downtime. Even our monitoring tools, such as Uptime, didn’t detect any issues. Most importantly, no users or candidates were affected by the process.
And this is how the MySQL Upgrade for HackerRank Community finally happened.


Shloka is a Senior Software Engineer at HackerRank. She is part of the Developer Community team and is responsible for all things backend and AI.
Leave a Reply